make_moons 데이터셋을 이용한 딥러닝 예제입니다. 데이터셋은 좌표 데이터구요. 각 데이터마다 0 또는 1의 라벨이 붙어있습니다. 데이터를 입력하면 0 또는 1로 분류해주는 신경망을 만드는 것이 목적입니다.
총 1000개의 데이터를 만들거구요. 750개를 훈련에 쓰고 250개는 테스트에 사용할 것입니다. 전체 과정은 아래와 같이 요약됩니다.

1. 패키지 설치
패키지가 설치되어 있지 않다면 콘솔에서 아래 피키지들을 설치합니다.
pip install sklearn
pip install scikit-neuralnetwork
pip install matplotlib
pip install pandas
pip install numpy2. 패키지 불러오기
사용할 패키지들을 불러옵니다. 코드는 아래와 같습니다.
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt3. 데이터 생성하기
make_moons 라는 함수를 이용하여 데이터를 생성합니다. from sklearn.datasets import make_moons 에서 불러온 함수입니다. 데이터를 생성하고 그래프로 그려보는 코드는 아래와 같습니다.
x, y = make_moons(n_samples=1000, noise=0.25, random_state=3, test_size=0.25)
plt.plot(x[y==1,0],x[y==1,1],marker='o',linestyle='',color='red')
plt.plot(x[y==0,0],x[y==0,1],marker='o',linestyle='',color='blue')
plt.show()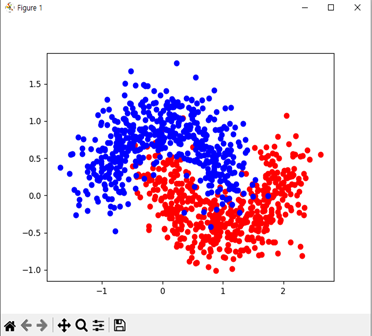
4. 트레인셋, 테스트셋 분리
train_test_split 함수를 이용하여 트레인셋과 테스트셋을 분리합니다. stratify=y 로 설정 시, target 의 비율을 유지해줍니다. random_state 값을 지정하면 수행시 마다 동일한 값이 추출됩니다. seed 를 고정하는 것입니다. test_size 는 테스트셋의 비율을 결정합니다.
코드는 아래와 같습니다.
#트레인셋 테스트셋 분리
x_train, x_test, y_train, y_test = train_test_split(x,y, stratify=y, random_state=42, test_size=0.25)
5. 딥러닝하기
MLPClassifier 함수와 fit 메소드를 이용하여 딥러닝을 합니다. 옵션에서 hidden_layer_sizes=(5,) 는 은닉층을 1층 사용하고, 뉴런을 5개 사용한다는 의미입니다. 은닉층을 3층 사용하고 뉴런을 5개씩 사용하면 hidden_layer_sizes=(5,5,5) 입니다. 모델을 훈련한 뒤 정확도를 확인합니다. 코드는 아래와 같습니다.
#객체 생성
mlp = MLPClassifier(hidden_layer_sizes=(5,),solver='lbfgs') #options : 'lbfgs','sgd','adam'
#모델 훈련
mlp.fit(x_train,y_train)
#정확도 확인
score_train=mlp.score(x_train,y_train)
print("train score : %0.2f" %score_train)
6. 평가하기
테스트셋을 이용하여 모델을 평가합니다. 코드는 아래와 같습니다.
#테스트셋을 이용한 평가
score_test=mlp.score(x_test,y_test)
print("test score : %0.2f" %score_test)
출력 결과는 0.9 정도 나올겁니다.
7. 테스트셋 결과 시각화
테스트셋의 결과를 시각화해봅시다. 코드는 아래와 같습니다.
y_result=mlp.predict(x_test) #테스트 데이터 라벨값
plt.plot(x_test[y_result==1,0],x_test[y_result==1,1],marker='o',linestyle='',color='red')
plt.plot(x_test[y_result==0,0],x_test[y_result==0,1],marker='o',linestyle='',color='blue')
plt.show()
#모든 코드 모아보기
#설치할 패키지
#pip install numpy
#pip insatll sklearn
#pip install scikit-neuralnetwork
#pip install matplotlib
#pip install pandas
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
x, y = make_moons(n_samples=1000, noise=0.25, random_state=3)
plt.plot(x[y==1,0],x[y==1,1],marker='o',linestyle='',color='red')
plt.plot(x[y==0,0],x[y==0,1],marker='o',linestyle='',color='blue')
plt.show()
#트레인셋 테스트셋 분리
x_train, x_test, y_train, y_test = train_test_split(x,y, stratify=y, random_state=42, test_size=0.25)
#객체 생성
mlp = MLPClassifier(hidden_layer_sizes=(5,),solver='lbfgs') #options : 'lbfgs','sgd','adam'
#모델 훈련
mlp.fit(x_train,y_train)
#정확도 확인
score_train=mlp.score(x_train,y_train)
print("train score : %0.2f" %score_train)
#테스트셋을 이용한 평가
score_test=mlp.score(x_test,y_test)
print("test score : %0.2f" %score_test)
#테스트셋을 이용한 결과 시각화
y_result=mlp.predict(x_test) #테스트 데이터 라벨값
plt.plot(x_test[y_result==1,0],x_test[y_result==1,1],marker='o',linestyle='',color='red')
plt.plot(x_test[y_result==0,0],x_test[y_result==0,1],marker='o',linestyle='',color='blue')
plt.show()'딥러닝 > 분류' 카테고리의 다른 글
| [파이썬 사이킷런 딥러닝] 분류 예제 (breast cancer) (0) | 2022.11.03 |
|---|

댓글