반응형
y값이 입력변수들에 의해 구분되어 있는지를 시각적으로 확인해보기 위해 산점도행렬을 그려봅시다.
지난시간에 만든 data_train이 입력변수입니다.
>>> data_train[:5]
array([[5.9, 3. , 4.2, 1.5],
[5.8, 2.6, 4. , 1.2],
[6.8, 3. , 5.5, 2.1],
[4.7, 3.2, 1.3, 0.2],
[6.9, 3.1, 5.1, 2.3]])
4열짜리 배열인데요. 판다스의 데이터프레임으로 바꿔야 산점도행렬을 그릴 수가 있습니다. 아래와 같이 바꿉니다.
df_data_train=pd.DataFrame(data_train)
>>> df_data_train[:5]
0 1 2 3
0 5.9 3.0 4.2 1.5
1 5.8 2.6 4.0 1.2
2 6.8 3.0 5.5 2.1
3 4.7 3.2 1.3 0.2
4 6.9 3.1 5.1 2.3
matplotlib 불러오고 그래프를 그려봅시다.
import matplotlib.pyplot as plt
pd.plotting.scatter_matrix(df_data_train,figsize=(15,15))
plt.show()

우리는 변수들 간의 상관관계가 궁금한 것이 아닙니다. 각 y값에 해당되는 점들이 잘 분리되어 있는지를 알고 싶습니다. y 값에 따라 색을 구분해주어야 합니다. c 옵션에 y값을 넣어주면 됩니다.
pd.plotting.scatter_matrix(df_data_train,figsize=(10,10),c=target_train)
plt.show()
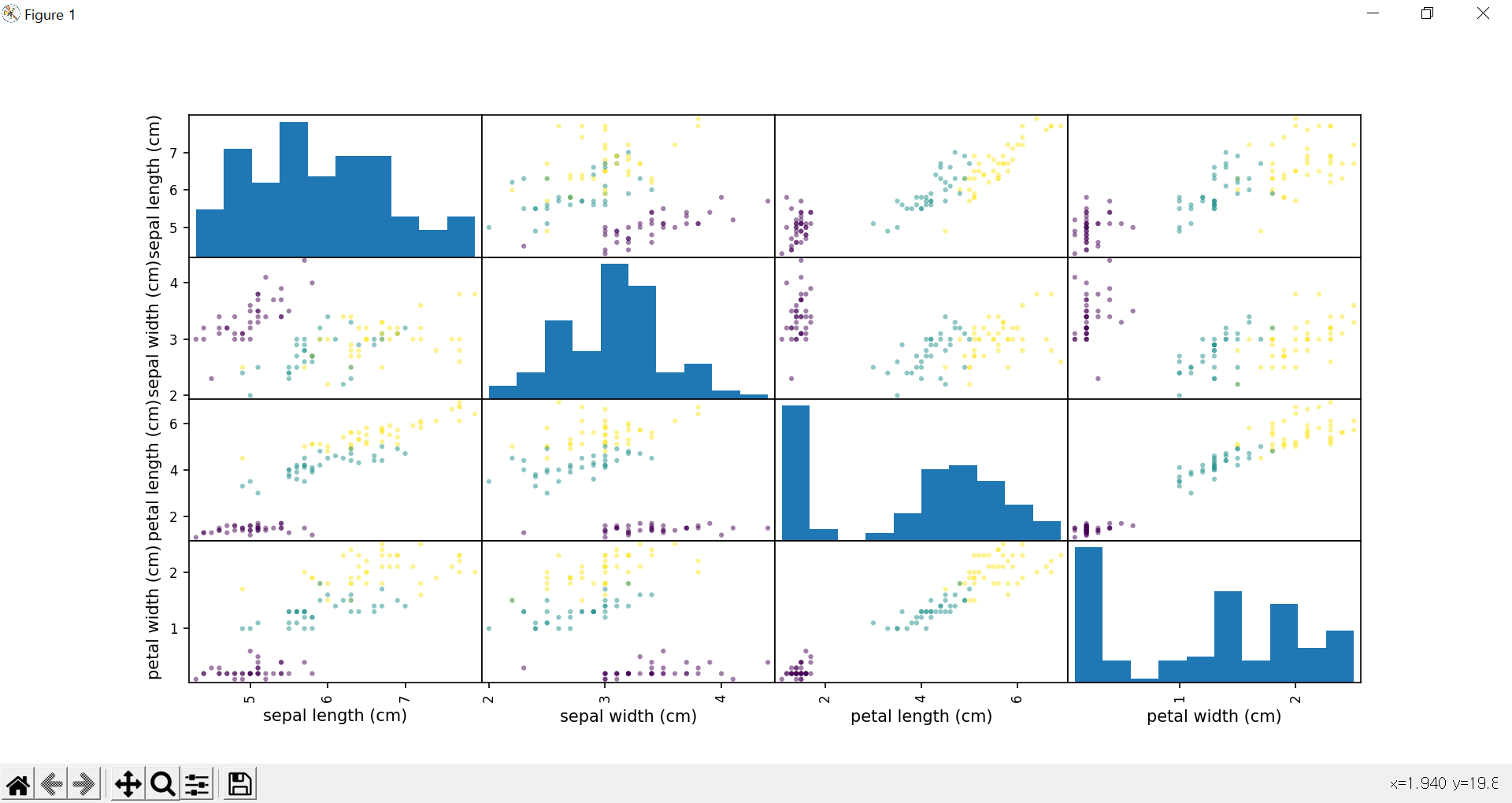
범례가 있으면 더 좋겠는데, 판다스의 산점도행렬에서 범례를 표시하는 것은 상당히 복잡합니다. 일단 넘어갑시다. 꽃 종류가 다르면 입력값에 따라 어느정도 구분이 되어 있는 것을 확인할 수 있습니다.
아래는 전체코드입니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
#데이터 불러오기
md=load_iris() #key:value 형태의 bunch 클래스, 딕셔너리와 비슷함
#데이터 분리해서 변수에 넣기
data_train,data_test,target_train,target_test=train_test_split(md['data'],md['target'],random_state=0)
#트레이닝 셋 x값들만 데이터프레임으로 만들기
df_data_train=pd.DataFrame(data_train,columns=md.feature_names)
#산점도행렬 그리기
pd.plotting.scatter_matrix(df_data_train,figsize=(10,10),c=target_train)
plt.show()
<참고문헌>
https://link.coupang.com/a/kHGzo
파이썬 라이브러리를 활용한 머신러닝:사이킷런 핵심 개발자가 쓴 머신러닝과 데이터 과학 실무
COUPANG
www.coupang.com
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
반응형
'머신러닝 (지도학습) > k최근접 이웃' 카테고리의 다른 글
| [파이썬 머신러닝, k최근접 이웃] 4. 모델 학습과 평가 (0) | 2022.03.24 |
|---|---|
| [파이썬 머신러닝, k최근접 이웃] 2. 트레이닝셋, 테스트셋 나누기 (0) | 2022.03.12 |
| [파이썬 머신러닝, k최근접 이웃] 1. Iris 데이터 살펴보기 (0) | 2022.03.10 |
댓글